








Forum de mathématiques - Bibm@th.net
Vous n'êtes pas identifié(e).
- Contributions : Récentes | Sans réponse
#1 Re : Café mathématique » Solution généralisée des tours de Hanoï (ou Toronto : 4 tours) » 28-01-2018 20:33:40
Bonsoir Choukos,
Merci de ta réponse. Le graphe ressemble bien à celui qui est visible dans le lien que tu donnes.
Par contre je ne comprends pas très bien l'algorithme de Dijkstra, et en tout cas il est suffisamment complexe pour que ce ne soit pas celui que j'avais implémenté selon les indications d'Olivier S. (je ne donne pas son nom de famille par souci de discrétion, et évidemment si j'avais son adresse je lui aurais posé directement la question)
De mémoire, tout tenait à la façon de coder une position, et à un calcul du genre addition bit à bit sans retenue, ou quelque chose de ce genre, pour trouver le premier coup du chemin menant à la position finale à atteindre.
Sauf bêtise de ma part, il n'y a que 3 coups possibles, deux déplacements possibles du plus petit disque et un déplacement d'un autre disque éventuellement (si nous ne sommes pas à une extrémité du graphe où tous les disques sont sur une seule tige).
Le calcul devait se faire sur les nombres représentant les positions immédiatement proches, et un de ces nombres devait avoir une particularité permettant de le reconnaître comme étant sur le chemin conduisant à la position finale.
C'est pour ça que je donnais les nombres représentant les sommets du triangle avec entre parenthèses ce qui semble être un reste modulo 3 de je ne sais quelle opération.
J'ai beau chercher, je ne vois pas comment on obtenait ce nombre représentant une position du triangle. Si tu veux je peux scanner la feuille où j'avais imprimé le graphe, mais il faudrait vraiment que je le fasse avec une haute résolution et je ne suis pas sûr que ça reste lisible comme il y a une minuscule représentation des 4 disques et de leur disposition sur les 3 tiges à chaque noeud du graphe, en plus du nombre et du 0..2 entre parenthèses.
Merci beaucoup de t'intéresser à ma question, je n'arrive pas à retrouver cette méthode et en plus d'être agaçant, ça m'arrangerait bien de la retrouver pour réécrire quelques tests cognitifs comme celui-ci.
Bien amicalement,
Milos
#2 Café mathématique » Solution généralisée des tours de Hanoï (ou Toronto : 4 tours) » 07-01-2018 02:06:34
- Milos
- Réponses : 3
Bonsoir à tous et bonne année,
Je cherche à retrouver une solution qu'un mathématicien (Olivier S., dont j'ai perdu les coordonnées) m'avait donnée vers 1988 à l'occasion de l'écriture d'un mémoire sur les aptitudes cognitives, notamment la résolution d'un casse-tête - celui de Hanoï.
Je pense que presque tout le monde le connaît : il s'agit de disques de taille décroissante, pouvant s'enfiler sur 3 tiges, et il faut depuis la position de départ où tous sont empilés sur la tige de gauche, les empiler sur celle de droite, sans jamais déplacer plus d'un disque à la fois, ni placer un disque plus grand au-dessus d'un plus petit. La position de départ est un empilement de 5 disques par ordre décroissant et donc toutes les positions suivantes n'ont que des disques empilés par taille décroissante sur chacune des 3 tiges (ou aucun disque comme les tiges du milieu et celle de droite au début).
Olivier S. m'avait fourni une méthode permettant, à partir d'une position quelconque, de trouver quel est le meilleur coup (au sens de celui donnant le chemin le plus court) pour atteindre une autre position quelconque.
L'algorithme qui en découlait était itératif et assez court, on lui passait la position codée de départ et celle de destination, et la fonction renvoyait le coup à effectuer. Il n'explorait rien, il ne s'agissait pas d'un algorithme récursif mis à plat, il ne faisait que considérer le codage de la position de départ et celle d'arrivée pour trouver le coup à jouer.
J'ai naturellement perdu les sources..
Il me semble, je n'en suis plus très sûr, que les positions faisaient l'objet d'un calcul rattaché à l'écriture de Gros-Gray, mais c'était peut-être autre chose : en tout cas, le code était compact.
Si ça peut aider, j'ai toujours par contre le graphe qui contient toutes les positions avec 4 disques en tout et permettait en fin d'expérimentation, de tracer en quelque sorte les errances des sujets testés au fur et à mesure de leurs essais.
En effet il n'y avait que 4 disques au lieu de 5, le casse-tête est alors surnommé les tours de Toronto et c'est cette variante qui a fait l'objet d'expérimentations sur des volontaires sains dans pas mal d'études sur les effets de médicaments ou placebo sur la mémoire. Il y a eu aussi quelques études sur des patients mais uniquement comparatives, pour tenter de trouver un pattern d'altérations cognitives rattachables à différentes pathologies. Ce test faisait naturellement partie d'une quantité d'autres tests et n'était pas effectué seul.
Le graphe est d'allure fractale, en forme de triangle dont ici les côtés font 15 longueurs, soit le chemin de résolution le plus court. La position du haut, avec les 4 tours à gauche est numérotée 0(0) sur mon graphe, celle du bas à gauche avec les 4 tours au milieu 121(1) et à l'opposé en bas à droite, celle avec les 4 tours à droite 242(2). Tous les nombres entre parenthèses sont entre 0 et 2.
Est-ce que vous pourriez m'aider à retrouver ce qu'Olivier m'avait indiqué ? (je vous préviens honnêtement que je suis totalement incapable de voir en quoi l'écriture de Gros-Grey peut aider, ou pourquoi il y a une similitude entre ce casse-tête et un baguenaudier : en somme que si je sais que ça ne se fait pas de demander des solutions toutes faites, je me permets une exception en espérant que vous me pardonnerez cette demande inspirée par la nostalgie autant que par le désir de réécrire un test cognitif sur les tours de Toronto).
J'espère donc que la question vous intéressera suffisamment pour chercher à retrouver ce que Olivier avait pu me dire..
Bien cordialement
Milos
#3 Re : Cryptographie » Code caché dans un lien ? » 07-01-2018 00:36:39
Bonsoir,
Je ne connais rien à la cryptographie, mais je me permets une réponse quand même comme ceci me rappelle un codage que j'avais fait pour les mots de passe des usagers d'un de mes programmes il y a bien longtemps.
Il s'agissait de permettre aux usagers de choisir eux-mêmes leur mot de passe, sans que je puisse moi-même en avoir connaissance.
J'avais tout bêtement utilisé un petit calcul de CRC32 comme on en trouve dans les vérifications de paquet en télécommunications : cet algorithme quand on utilise les coefficients polynomiaux recommandés (par le CCITT je crois) de s'approcher du risque de collision minimal.
Ce que je veux dire est que ce nom de fichier pourrait bien être le résultat d'une transformation irréversible et que même en connaissant la méthode utilisée, on peut être renvoyé à la force de calcul brute pour trouver un mot de passe qui donne le même résultat.
Cordialement,
Milos
#4 Re : Café mathématique » Numérologie apocalyptique » 29-10-2016 14:01:04
Cher Freddy et cher JPP,
Effectivement 666 serait le chiffre de la bête ou quelque chose comme ça, je dois avouer que je n'ai jamais réussi à lire l'Apocalypse de Saint-Jean.
Et JPP tu as raison bien sûr, c'est 36 et pas 34, je n'avais pas été revoir la vidéo YT dont l'auteur cite ce calcul.
Merci à toi de tes exemples et contre-exemples (avec 666, 6666 et 333, 333)
A vrai dire, la numérologie m'amuse plutôt, mais sa conjonction avec l'apocalypse par des gens qui prétendent que les avions des tours jumelles étaient en fait un hologramme (c'est fou de voir le nombre de gens qui le pensent) et qu'il faut qu'on se repente d'urgence..
Si j'ai bien compris, 777 serait lui un nombre très bénéfique. J'ai essayé de tripatouiller des dates à venir pour prédire l'anti-apocalypse mais sans succès..
Par contre, pour l'hologramme des avions, j'ai découvert la vérité : c'était en fait les tours jumelles qui étaient un hologramme. Son propriétaire a trouvé ce moyen pour faire un bénéfice sur le coût de la construction.
Amicalement
#5 Café mathématique » Numérologie apocalyptique » 28-10-2016 23:01:08
- Milos
- Réponses : 3
Bonsoir,
Je vois des vidéos sur YT qui s'obstinent à trouver des 6 ou 666 partout.
Par exemple, la somme des 34 premiers vaut 666 et celle des carrés des 34 premiers 666 au carré, l'auteur n'ayant pas remarqué que cette égalité est générale qu'il s'agisse des 34 premiers nombres ou de n'importe quelle autre nombre que 34 (mais ne donnant évidemment plus 666, d'ailleurs pourquoi 34 est-il privilégié est encore plus mystérieux que pourquoi 666).
Il va de soi que le même fait tout son possible pour en trouver d'autres avec les 6 premiers nombres premiers en excluant je ne sais pourquoi et lui non plus sans doute 2 de la liste des nombres premiers, etc..
Je me demandais si pour tourner légèrement en ridicule ce genre de calculs, vous sauriez me donner
- une tripotée de calculs donnant 666
- à l'inverse d'autres tripotées de calcul donnant aussi bien 111, ou 777, ou 333, ou ce qu'on voudra ?
Merci à vous si ce genre de sujet vous intéresse (je veux dire tourner ces numérologues en dérision)
Amitiés.
[EDIT] Je veux dire des tripotées de calculs "d'allure (vaguement) mystique"
#6 Re : Programmation » [Maple] Aide aux utlisateurs débutants (ou pas) » 26-10-2016 19:44:26
Oups ! Pardon, je suis vraiment nul et inattentif.
Merci et amicalement, Milos
#7 Re : Programmation » [Maple] Aide aux utlisateurs débutants (ou pas) » 26-10-2016 19:00:09
Cher Léon,
Ca fonctionne effectivement mais un point m'échappe dans la sortie :
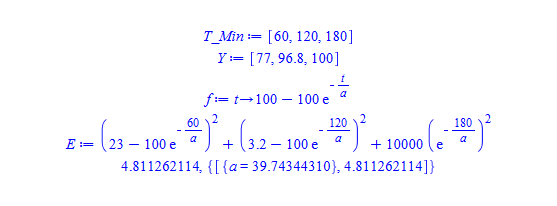
Je comprends les deux premières valeurs (100-77 = 23, 100-96.8=3.2) mais pourquoi ce 10000 pour la troisième ? Avec 100-100=0, je ne vois pas pourquoi on n'a pas ((0-100 exp(-180/a)^2) ?
Merci de ton aide, amicalement
#8 Re : Programmation » [Maple] Aide aux utlisateurs débutants (ou pas) » 25-10-2016 22:58:47
Bonsoir Léon,
C'est quand même extraordinaire, ton code tient en 4 lignes (quelle que soit le nombre de valeurs si je l'ai bien compris), et les auteurs de Maple ne semblent pas l'implémenter même on option !
En passant, si ta version de Maple est ancienne, comme toi tu sais te servir très bien de Maple, contrairement à moi et c'est le moins qu'on puisse dire, si tu ne t'en sers pas à titre professionnel, contacte moi pour t'en procurer une version très légale que je serais heureux de te donner, tu fais oeuvre de salubrité publique.
Amicalement.
#9 Re : Programmation » [Maple] Aide aux utlisateurs débutants (ou pas) » 23-10-2016 20:20:51
Bonsoir Léon et merci,
donne
a = 39.74344310 , meilleur que 43.5 !
C'est assez stupéfiant, comme la méthode de Maple en donnant un sérieux indice donnait à quelques décimales près la même chose:
39.74344257 au lieu de ce tu obtiens, 39.74344310 !
Mais qu'est-ce que signifie dans ton code auquel je ne comprends rien de rien "nops(Y)", ou "location" ?
Un grand bravo à toi en tout cas
Merci encore,
#10 Re : Programmation » [Maple] Aide aux utlisateurs débutants (ou pas) » 23-10-2016 18:45:02
Salut Léon,
Et merci de bien vouloir m'aider
Ta famille 100 ( 1- exp(-t/a)) n'est stable que par homothétie sur les X... Il faudrait mettre " c+b.exp(t/a) "
Dans ce cas Maple produit : t -> 100.6 - 146.1 exp(-0.03 t)
En fait, la courbe passe nécessairement par (0,0), j'ai d'ailleurs essayé en ajoutant ce couple aux 3 valeurs.
Je te montre les courbes que les (ou la) publication ont (a) ainsi modélisé (je veux dire avec a = 43.5) Je regarde juste si une valeur moindre de a ne serait pas meilleure)
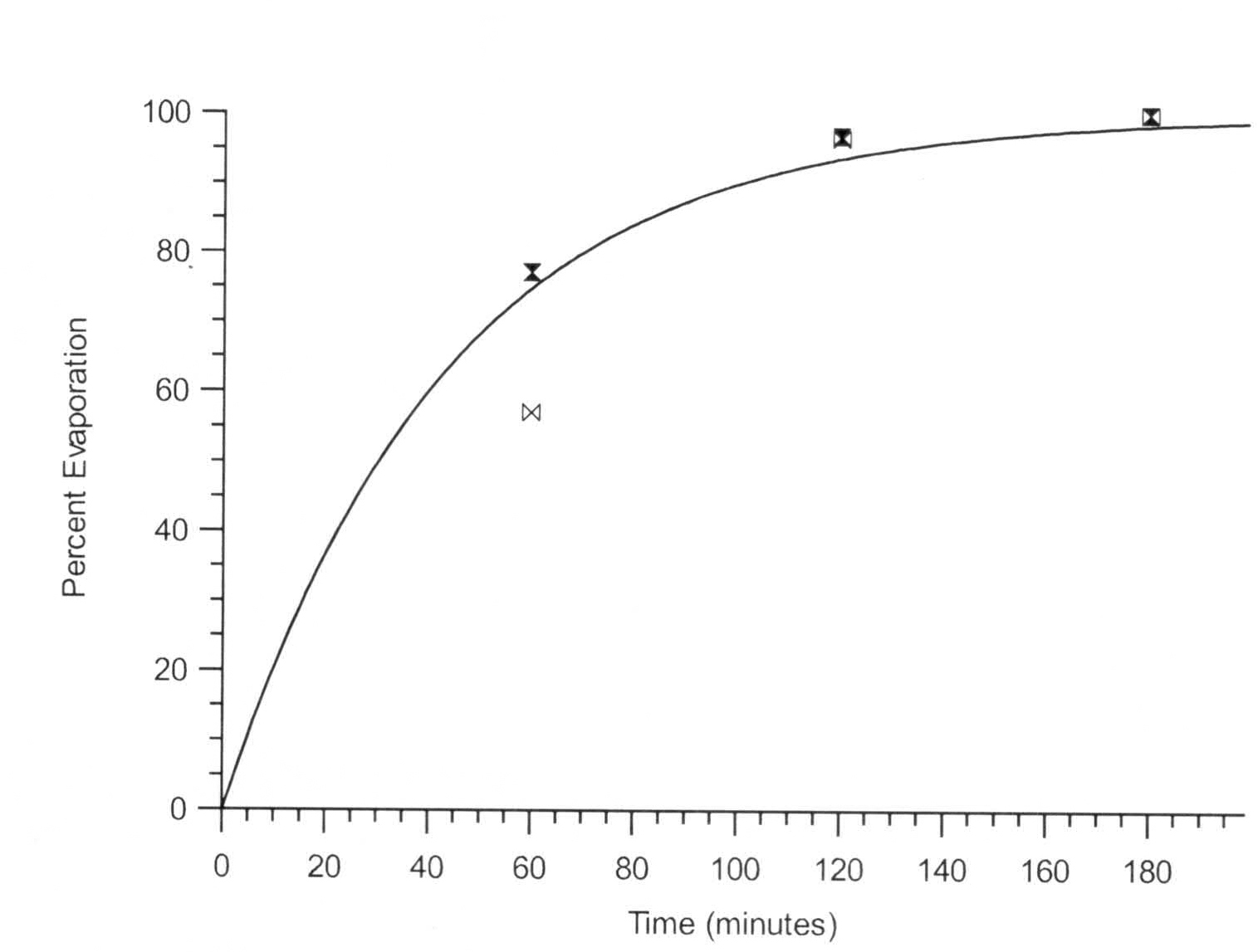
On peut penser tout le mal qu'on veut du modèle, en prendre n'importe quel autre, mais la seule chose sûre est que la courbe doit passer par (0,0) comme au temps 0 rien ne s'est encore évaporé du support.
Ce qui est curieux est qu'il y a une dizaine d'années et plus, même moi je trouvais je ne sais plus comment que a avec 43.5 n'était pas parfait, qu'une valeur un peu moindre était meilleure.
Mais je ne sais plus du tout comment j'avais fait, je n'ai aucun souvenir d'avoir acheté du papier semi-log, ..
Si on maintient ce modèle que je veux vérifier, quitte à le faire à la main comme Maple ou Mathematica sont en déroute, comment ferais-tu ?
Amitiés,
#11 Re : Programmation » [Maple] Aide aux utlisateurs débutants (ou pas) » 23-10-2016 16:03:45
Salut Freddy ,
Salut Milos,
je t'ai envoyé une adresse mail, il me semble :-)
Je l'ai bien recue, et je t'en remercie beaucoup.
Je suis justement en train de mettre en forme un message à ton intention, avec des précisions (notamment sur les "imprécisions". -)
Merci encore et amicalement
#12 Re : Programmation » [Maple] Aide aux utlisateurs débutants (ou pas) » 23-10-2016 13:34:42
Re-bonjour Freddy,
Je me demande si cette difficulté algorithmique ne serait pas liée à la fonction elle-même en regard des données fournies ?
Je viens d'essayer avec Mathematica, qui avec la fonction FindFit me propose a=11. Avec 11 la courbe passe toujours très au large des deux points à 60 et 120.
#13 Re : Programmation » [Maple] Aide aux utlisateurs débutants (ou pas) » 23-10-2016 12:15:11
Cher Freddy,
Si ta version de Maple est ancienne, tu n'as sans doute pas les nouveautés qui auraient été ajoutées dans les versions 2015 et 2016 concernant des fonctions statistiques : l'aide explique que Fit choisit (d'elle-même apparement) entre deux fonctions, LinearFit et NonlinearFit, et on peut ajouter des valeurs initiales aux paramètres, qui servent apparemment de point de départ au calcul d'ajustement.
Du coup, j'ai essayé d'ajouter a=45 comme valeur initiale, et ça me donne ça :
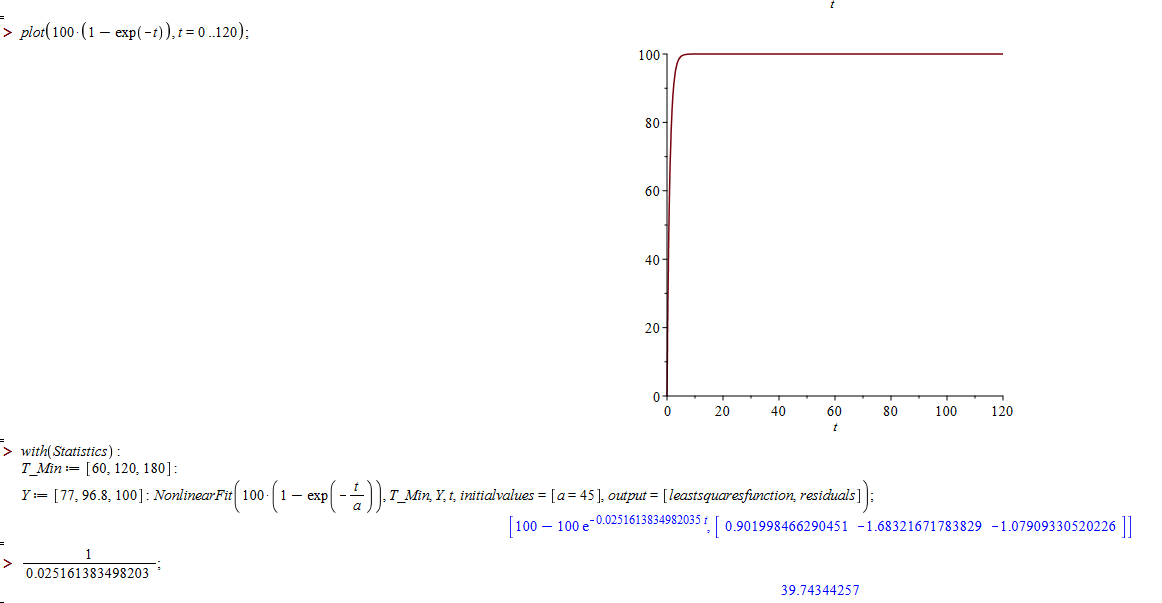
Donc cette fois Maple estime a à 40 environ..
Je n'y comprends trop rien, c'est à croire que l'algorithme de Maple est inefficace au point qu'il faut lui donner un sérieux indice pour chercher une solution minimisant les moindres carrés..
Amicalement
#14 Re : Programmation » [Maple] Aide aux utlisateurs débutants (ou pas) » 23-10-2016 11:04:47
Bonjour Léon,
Merci d’abord de ton aide pour Maple, je débute depuis des années.. (il est vrai que j’ai aussi Mathematica, ils font tous les deux des prix autour de 300€ pour les gens qui n’en ont pas un usage professionnel, pour Mathematica ils me croient sur parole, pour Maple j’ai quand même un commercial qui m’a téléphoné à répétition, ils sont moins confiants).
Donc tu as résolu mon problème pour la fonction fit, mais c’est le résultat qui me fait souci, comme c’est invariablement environ 1..
En fait je me suis trompé, la fonction à ajuster est 100*(1-exp(-t/a)), elle est censée exprimer en % la fraction évaporée d’un substrat avec t en minutes (j’ai un tableau avec l’évolution de ces fractions selon quelques températures). La validité du modèle n’a pas d’importance comme il ne s’agit pour moi que de contrôler une formule publiée d’après les données à 15°C, où a vaut 43.5.
Ici, la fonction renvoyée par Maple donne 100% à peu près en 60 minutes, la formule publiée donne 75%, et le tableau que tu peux voir en haut de la copie d'écran, indique les 77% en 60 minutes utilisés pour l'ajustement.
La capture d’écran te montre la « petite » différence : est-ce normal que Maple se trompe aussi lourdement ou est-ce normal avec ces malheureuses 3 petites données ? Je n’en ai pas l’impression comme le tableau donne jusque 5 données à des températures plus basses et que le paramètre a estimé par la fonction fit ne change pas. Mais d’un autre côté, 100% avec ce modèle étant impossible, je ne sais plus trop.
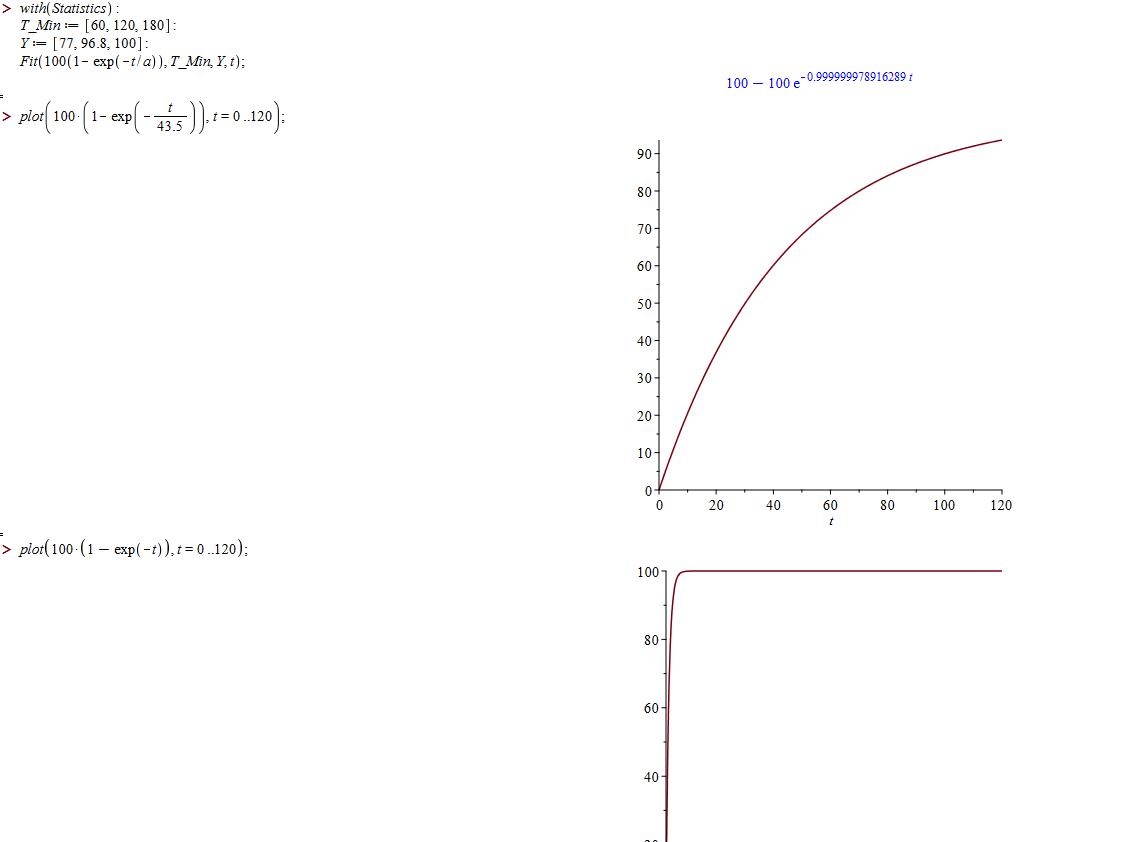
Qu’en penses-tu, ai-je fait une erreur de syntaxe de plus, est-ce la méthode d’ajustement de Maple qui donne ces résultats invariables quand on a des 100% qui apparaissent (tout ce que je lis dans l’aide est que fit minimise les moindres carrés).
Merci de ton aide, et bien cordialement,
#15 Re : Programmation » [Maple] Aide aux utlisateurs débutants (ou pas) » 22-10-2016 23:32:34
@Cher Léon,
Il se fait tard, mais je reviendrai vers toi pour un "petit" problème : dans la famille d'exemples (en remplacant l'exponentielle de -t par 100 fois (1-la même), quoi que je donne pour les trois points (c'est le minimum syndical certes), a vaut toujours 1 environ, alors que le dessin de la fonction montre que ça ne va pas du tout.
Une bonne nuit de sommeil aidera à y voit plus clair..
Cordialement,
Milos
#16 Re : Programmation » [Maple] Aide aux utlisateurs débutants (ou pas) » 22-10-2016 22:11:41
Merci Léon,
Je vois que toute la différence tenait au fait que j'utilisais "=" et pas ":="..
Et du coup je retrouve tes résultats.
Merci encore et bien cordialement;
#17 Re : Programmation » [Maple] Aide aux utlisateurs débutants (ou pas) » 22-10-2016 22:04:07
Salut,
Bien, c'est que je ne voudrais pas troller moi-même..
D'un autre côté, c'est bien de ne pas faire reposer sur Léon tout seul des réponses que sans doutes d'autres lecteurs du forum peuvent donner aussi..
Amitiés,
#18 Re : Programmation » [Maple] Aide aux utlisateurs débutants (ou pas) » 22-10-2016 20:49:06
Bonsoir,
Si tu penses que le topic est superflu, pas de souci, on peut le supprimer (j'ai évidemment cherché dans l'aide en ligne et au-delà, c'est le minimum pour respecter les autres - et soi-même aussi d'ailleurs - ne pas aller solliciter les autres avant d'avoir fait le maximum soi-même pour trouver)
Merci pour le lien
Milos
#19 Programmation » [Maple] Aide aux utlisateurs débutants (ou pas) » 22-10-2016 20:18:27
- Milos
- Réponses : 30
Maple a l'air d'être un programme très efficace, mais pas toujours facile à utiliser.
D'autant plus qu'il ne fait pas de vérification syntaxique au cours de la frappe, et que les messages d'erreur sont cryptiques, enfin pour moi; et qe souvent il renvoie l'expression de départ, sans que je sache si ça siginifie que le problème est insouble, ou qu'il fallait des instructions supplémentaires pour avoir des réponses.
Et leur communauté Maple qui était bien sympathique et efficace, ne répond pus beaucoup.
Je propose donc d'ouvrir un topic comme il y a ici manifestement des utilisateurs chevronnés, afin d'aider des usagers très (comme moi) débutants, ou expérimentés.
Une première question par exemple:
Je cherche simplement le paramètre pour ajuster des données, l'aide de Maple dit que l'instruction fit fait ça avec la méthode des moindres carrés (ou peut-être d'autres méthodes, le programme a tant de fonctions et d'options..)
Donc simplement 3 paires de données à ajuster si possible à la fonction e^-t/r :

Si on pouvait m'aider à comprendre ce qui ne va pas..
Merci à tous
#20 Re : Café mathématique » Fond du problème des probabilités (titre probisoire) » 22-10-2016 07:29:24
Ce qui est réellement désolant est que Milos marche dans ta combine.
..
.. puisqu'ils n'apparaissent que moins de 2% des cas.
Je ne marche dans aucune combine, ma réponse est clairement que ces données ne suivent pas une loi normale, et que ce n'est pas du à une anomalie quelconque dans le comptage qui a fourni ces données.
J'avais déjà donné cette réponse mais ça semble vous avoir échappé.
Si vous croyez dur comme fer qu'elles devraient suivre une loi normale alors qu'elles ne le font pas. je n'y peux rien.
Pour ce que vous explique abondamment Léon, il me semble évident qu'avoir en un seul tirage un événement qui survient en moyenne 2 fois sur mille exclut en pratique l'hypothèse H0 (à vrai dire, exclure H0 au risque d'erreur 5% est l'habitude qu'on m'a enseignée, même si parfois un seuil plus bas est prévu pour l'étude).
#21 Re : Café mathématique » Fond du problème des probabilités (titre probisoire) » 21-10-2016 20:09:46
Bonjour Milos,
Vous avez oublié de répondre à ma question "Sans être curieux, j'aimerais bien savoir ce que vous en déduisez, que votre liste est fausse ou que la loi normale est une escroquerie ?".Je sais que j'écris mal, mais quand j'écris "je ne sais pas comment ont été calculées vos courbes" ça ne veut absolument pas dire "[alors que vous venez de dire que] vous ne savez pas comment on calcule ce genre de courbes ?" .
Chacun sait que les maths demandent de la rigueur, et les échanges en individus en demandent au moins autant.
J'indique le mode de calcul que tout le monde connaît, en ajoutant un tri qui prend très peu de temps et permet aussi d'avoir ensuite d'emblée la médiane, les quantiles, et quantité d'autres choses en un nombre minimum de passes.
Et si j'indique la méthode, c'est bien évidemment parce que les programmes dédiés utilisent sans doute ce genre de méthode voire des variantes optimisées, mais aussi que en cas de doute, dans un cas aussi simple,où vous prétendez que soit la liste est fausse, soit la loi normale une escroquerie, il est quand même bien plus logique, c'est même la seule supposition possible, qu'un programme dédié est buggé. On peut vérifier soi-même quelques résultats dans des cas aussi simples que celui-ci.
Pour votre question, figurez-vous qu'un ensemble de données peut ne pas suivre une loi normale, voire même une loi qu'on n'arrive pas à trouver (quoique j'ignore par exemple si l'utilisation de chaînes de Markov peut donner une réponse, enfin je veux dire donner à tout coup une méthode générant une série de données "donnée", si un mathématicien-statisticien compétent comme en on trouve ici pouvait me donner son avis..)
Il existe dans XLSTAT par exemple un outil choisissant automatiquement les lois (parmi celles pré-fixées qu'il connaît) ne pouvant être exclues devant l'ensemble de données que j'avais cité.
Cet outil donne ici:
Binomiale négative (2) 0,331
Gamma (2) 0,355
GEV 0,365
Log-normale 0,399
Logistique 0,221
en utilisant le maximum de vraisemblance. Je n'ai gardé que les valeurs les plus élevées.
La loi log-normale est compréhensible (enfin, pour moi) comme elle aplanit les anomalies en excès (mais aussi tout le reste)
J'aurais bien du mal à dire pourquoi les autres lois seraient adaptées, mais enfin elles seraient acceptables selon la maximum de vraisemblance.
Ce calcul peut utiliser aussi la méthode des moments, qui donne en gros les mêmes lois relativement acceptables.
#22 Re : Café mathématique » Fond du problème des probabilités (titre probisoire) » 20-10-2016 22:42:39
Je suppose que c'est toujours à moi que vous vous adressez
Par ailleurs, comme je sais pas comment ont été calculées vos coubres, et je le suppose, vous non plus, on en est revenu au même point : votre question initiale, les régressions linéaires.
"comme je sais pas comment ont été calculées vos coubres, et je le suppose, vous non plus" : vous plaisantez ? pour les histogrammes d'effectif c'est trivial, il suffit d'ordonner les données, de diviser en n tranches, et de compter, etc.. Et pour superposer la loi normale, puisqu'il faudrait absolument que ça en soit une plutôt qu'une sigmoïde par exemple, calculer la moyenne, l'écart-type, etc..
"et vous non plus je suppose" ? Et ça serait moi qui ne saurais rien de rien alors que vous venez de dire que vous ne savez pas comment on calcule ce genre de courbes ?
Pour votre supposée "escroquerie" de la répartition normale (car vous supposez sans cesse une répartition d'effectif normale), allez donc voir simplement sur Wikipédia "fonction logistique", vous verrez une répartition qui ne l'est pas du tout, avec des suppositions raisonnables pour certains problèmes, mais aussi des applications réelles dans certains réseaux neuronaux par exemple. Et certainement des données réelles suivant cette répartition, je n'ai pas le temps d'en chercher.
#23 Re : Café mathématique » Fond du problème des probabilités (titre probisoire) » 20-10-2016 20:41:07
Cher Freddy,
Tu as entièrement raison, j'ai vu récemment une grande délirante qui a appelé les pompiers à 3h du matin parce qu'elle avait mal aux pieds (elle était aphone avec des ampoules aux pieds à force d'aller chanter et autre dans la campagne du coin).
Quand j'ai dit par humour que ce n'était rien que de normal, appeler à 3h du matin les pompiers pour des ampoules aux pieds, elle a été étonnée et m'a dit : "alors elle rentre ?"
Elle m'a expliqué n"avoir pas compris que je plaisantais parce qu'ils se font réellement appeler rien que pour des maux de pied, et pas rarement en plus..
#24 Re : Café mathématique » Fond du problème des probabilités (titre probisoire) » 20-10-2016 19:27:34
Cher Léon,
Milos a écrit :Le graphe ci-dessous montre comme le total suit une loi supposée "des grand nombres" (normale ?) :
http://nsm08.casimages.com/img/2016/10/ … 567292.jpgMilos,
pour analyser les données, pourquoi n'utilises-tu pas la fonction de répartition de la loi normale, plutôt que sa fonction de densité ?
Utiliser la fonction de densité implique de faire des classes, ce qui reste assez subjectif. En plus, le résultat peut-être bruité, ce qui nuit à la lecture du graphe. Utiliser la fonction de répartition ne nécessite pas de classes et permet d'employer le test de Kolmogorov (et autres déclinaisons que vous connaissez).
Non ?
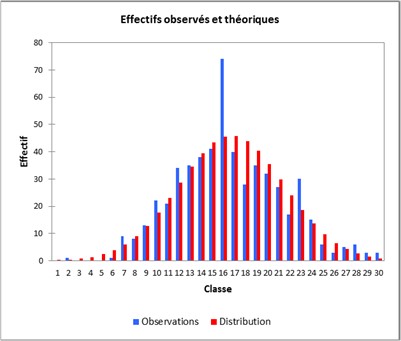{kind=link}
Tu as raison, bien sûr que si. Je ne donnais ce graphe que pour montrer une anomalie flagrante que même d'"autres" puissent comprendre (s'ils voulaient admettre que 30 classes n'a pas été choisi délibérément comme anomalie singulière - pas envie de perdre du temps avec 28 ou 32 classes pour montrer que l'anomalie plus que visible persiste)
Bien à toi,
Milos
#25 Re : Café mathématique » Fond du problème des probabilités (titre probisoire) » 20-10-2016 19:06:05
Cher Léon,
Dlzlogic a écrit :Les moyennes sont assez comparables, sauf que les jours 2 et 3 qui paraissent plus élevés.
leon1789 a écrit :2 jours sur 7 qui sortent du lot, cela pose des questions. En tout cas, on ne peut pas les balayer simplement, comme ça...
A noter que les jours 2 et 3 sont les samedis et les dimanches.. Cela montrerait que les weekend sont plus accidentogènes que le reste de la semaine (ce qui est vrai, me semble-t-il).
Les explications des samedi-dimanche peuvent varier. Effectivement, plus de sorties, de sport, plus d'accidents. Ou alors les généralistes ont fermé boutique, donc on va aux urgences, ou les deux à la fois.
Je suis allé voir à l’œil nu des jours fériés, je ne crois pas que quelque chose en ressorte, parfois vraiment beaucoup d'urgences, parfois peu.
On pourrait aussi évoquer les vacances scolaires, les ponts, se dire que les gens sont en vacances ailleurs ou ici (en plus ou en moins selon que c'est une région effectivement touristique, mais que les locaux iront assez loin, dans de la famille, etc..)
Je ne sais pas faire ce que propose Freddy, distinguer dans une série temporelle les fériés, etc.. avec un outil statistique qui distinguerait ces dates.
En fait, le responsable du DIM de cet hôpital m'a fourni ces données très simples, parce que je ne cherchais qu'à m'entraîner aux analyses de tendance, attendant que notre propre responsable DIM me fournisse nos propres données, avec des effectifs moyens journaliers très bas mais sur 6 ans.
Je ne sais pas s'il est possible de faire une analyse de tendance "valable" jour après jour sur une série de 6 ans, avec par exemple une loi de Poisson dont la moyenne serait 2.
En tout cas, c'est uniquement pour ça que je demandais ces données.
Pour une analyse supposément causale, il aurait fallu le diagnostic, l'âge, la distance entre l'hôpital et le lieu de résidence habituel, que sais-je..
Mais comme je ne voulais que m'entraîner à une analyse de tendance, voir les lois de répartition, je n'ai pas demandé (et je n'aurais pas sans doute obtenu plus, à moins de démontrer une méthodologie valide au responsable DIM, et encore, en supposant que le problème l'intéresse et son hôpital aussi - pourquoi d'ailleurs dans ce cas ne ferait-il pas l'étude lui même ?)
Donc pour revenir à l'excellente question de Freddy : je n'ai demandé et obtenu ces données, que pour vérifier si une distribution genre Poisson s'adaptait (ce n'est pas le cas, je le sais maintenant), et pour m'entraîner à ce genre d’analyse en regardant d"éventuelles tendances.
Amitiés à toi